破解股市泡沫之谜——对数周期幂率(LPPL)模型
来源:https://uqer.io/community/share/567a4fbd228e5b344568810f
引言
虽然离开物理专业有好几年了,但一直有些念念不忘,码着代码,写着开题报告,又闲不住想来讲一个没有好奇心的物理学家不是好金融学家的故事。
发现金融泡沫并预测到其何时破裂是很多从事金融行业的人的梦想。如今中国股市也成为了热门的话题,然而,资本狂欢之后是股灾,多少人因此从千万富翁炒股变成百万富翁,预测泡沫是所有人的梦想。
我们的主角Sornette教授登场了。Didier Sornette是一位受过培训的统计物理学家和地球物理学家,目前在瑞士联邦理工学院苏黎世分校(Swiss Federal Institute of Technology in Zurich)任金融学教授,主讲创业风险。他似乎并没有因外界对这种综合学科研究方法的热情有所减弱而感到烦恼。相反,他还在做自己大部分职业生涯一直在做的事:不仅在主要物理期刊上发表文章,还在领先的金融期刊上发表文章。
Sornette教授开始尝试着解答这个问题——不是通过传统的金融学方法,而是将物理学思想引入其中。作为2004年出版的《股市为什么会崩盘》(Why Stock Markets Crash)一书的作者,Sornette教授实质上是希望更深刻地理解泡沫的形成和发展。在对复杂体系的分析中,他独自——或者是和极少数几个人一起——引领着三个并行领域:纯物理学、应用经济学和计量经济学,以及市场从业人员。
在《股市为什么会崩盘》一书中,Sornette教授全面分析了一个由其提出的预测市场泡沫的模型——对数周期幂律(LPPL)模型。该模型对之后许多次市场泡沫都进行了准确的预测,由于该模型由Johansen,Ledoit和Sornette共同提出并完善,因此也被称为JLS模型。我们来聊一聊它。
什么是对数周期幂率模型?
作为纯物理学家的Sornettee教授不甘于仅仅在物理学领域有所建树,他还看到了金光闪闪的华尔街,在那里,各类炼金术师在寻找各种允许少数人持续获利的方法。于是,Sornettee教授在金融领域的跨界之旅开始了。他脑洞大开,想将物理学模型延伸到金融学领域中,而他找到的第一把金光闪闪的钥匙叫做易辛模型——一种描述物质铁磁性的经典模型。简单地说,易辛模型认为单个原子的磁矩只可能有两种状态,+1(自旋向上)或者-1(自旋向下),原子以某种规则排列着,并存在着交互作用,使得相邻之间的原子的自旋互相影响。
Sornette教授的眼睛仿佛一下子充满了光芒,他仿佛看到了美元纸币上的林肯在向他招手。受易辛模型启发,Sornette教授认为在金融市场中,投资者也只具有两种状态,即买或者卖。同时,投资者的交易行为取决于其他投资者的决策及外部因素的影响,这与易辛模型是多么的相似!
假想我们处于这样的一个市场中:资产没有派息、银行利率为零、市场极度厌恶风险,并且市场有着充足的流动性。显然,在这个市场中的金融资产没有任何价值,也就是其基础价值为零。在这样的框架内,市场中出现两类投资者,如上文所说,一类是理性投资者,一类是非理性的噪声投资者。后者具有羊群效应,使得金融资产价格偏离其基础价值,在没有足够的做空机制下,该结果导致理性投资者也不得不跟随噪声投资者的行为,通过享受泡沫来获得收益。最终当趋势达到某一临界值时,大量投资者没有足够的头寸维持该趋势,于是手中的卖单导致了市场的崩盘。
那么这是一个怎样的趋势呢?Sornette教授考虑了自激励的正反馈过程的思想,而该过程会导致大量交易者的行为方式逐渐趋于一致。在经过一些推导之后,Sornette教授发现该趋势是按对数周期幂律(LPPL)增长,这里给出唯一的也是最重要的公式。
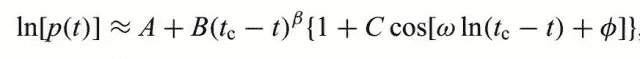
这里不去探讨该公式的具体意义,让我们看一下它的样子。
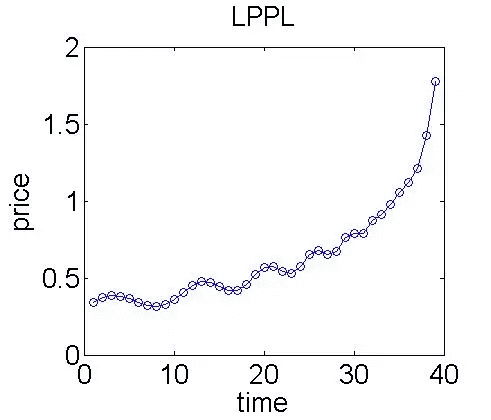
可以看到,随着时间增长,资产价格有着近似指数增长的特点,但同时也伴随着不断的振荡,随着时间越来越接近临界时间,振荡的幅度逐渐减小,增长速度逐渐增大,进入超指数的增长状态,最终市场在临界时间点附近崩盘。通过该模型,人们可以提前获知可能的临界时间点来规避风险。该模型曾成功预测了2008年的石油泡沫,美国房地产泡沫,以及2009 年中国股市泡沫等。
然而,试图根据泡沫迹象采取行动的交易员,现在或许会非常失望。正如Sornette教授自己承认的,其理论实际上旨在估计这种泡沫的存在时间,而过早退出市场将是个错误,很可能会损失大量资金,然而离开过晚就不是几个人失去工作的事了。事实上,该模型并没有考虑交易者以外的因素,比如政策层面或者市场情绪等因素,但将金融系统认为是一个复杂系统并加以研究的思想是深远的。现在也有许多将语义情绪分析等类似机器学习的方法应用于模型中来对市场状态进行分析。
毫无疑问,更多地了解泡沫的形成和发展,价值是无法估量的。关注经济和金融以外的领域有助于拓展思路,但不要指望找到一个指导市场交易的万能公式。
LPPL模型收到的批评与收到的赞扬一样多,有不少人认为该模型没有操作价值。如果你想了解更多关于它的信息,可以仔细详读Everything You Always Wanted to Know about Log Periodic Power Laws for Bubble Modelling but Were Afraid to Ask。
最后,如果你有好奇心,那么你一定想知道LPPL模型的实战结果到底如何。下面我用优矿再现了LPPL模型预测2015年夏天A股市场的泡沫。
P.S 这次股灾虽然我逃顶了,也许我马后炮了~ :)
使用DataAPI.MktIdxdGet()函数获取上证指数2014年1月1日至2015年6月10日的指数信息(股灾发生在约一星期后)。lib库我也放在了文章最后,大家可以尝试着使用。特别感谢jd8001,用于拟合的GA算法的核心代码框架来自于他,我对参数设置做了细致的调整,以让它更好的符合A股市场,最后我友好地加上了一些注释。
import lib.lppltool as lppltool
from matplotlib import pyplot as plt
import datetime
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_style('white')
limits = ([8.4, 8.8], [-1, -0.1], [350, 400], [.1,.9], [-1,1], [12,18], [0, 2*np.pi])
x = lppltool.Population(limits, 20, 0.3, 1.5, .05, 4)
for i in range (2):
x.Fitness()
x.Eliminate()
x.Mate()
x.Mutate()
x.Fitness()
values = x.BestSolutions(3)
for x in values:
print x.PrintIndividual()
Fitness Evaluating: 0 of 20
Fitness Evaluating: 1 of 20
Fitness Evaluating: 2 of 20
Fitness Evaluating: 3 of 20
Fitness Evaluating: 4 of 20
Fitness Evaluating: 5 of 20
Fitness Evaluating: 6 of 20
Fitness Evaluating: 7 of 20
Fitness Evaluating: 8 of 20
Fitness Evaluating: 9 of 20
Fitness Evaluating: 10 of 20
Fitness Evaluating: 11 of 20
Fitness Evaluating: 12 of 20
Fitness Evaluating: 13 of 20
Fitness Evaluating: 14 of 20
Fitness Evaluating: 15 of 20
Fitness Evaluating: 16 of 20
Fitness Evaluating: 17 of 20
Fitness Evaluating: 18 of 20
Fitness Evaluating: 19 of 20
fitness out size: 20 0
Eliminate: 14
Mate Loop complete: 25
Mutate: 2
Fitness Evaluating: 0 of 31
Fitness Evaluating: 1 of 31
Fitness Evaluating: 2 of 31
Fitness Evaluating: 3 of 31
Fitness Evaluating: 4 of 31
Fitness Evaluating: 5 of 31
Fitness Evaluating: 6 of 31
Fitness Evaluating: 7 of 31
Fitness Evaluating: 8 of 31
Fitness Evaluating: 9 of 31
Fitness Evaluating: 10 of 31
Fitness Evaluating: 11 of 31
Fitness Evaluating: 12 of 31
Fitness Evaluating: 13 of 31
Fitness Evaluating: 14 of 31
Fitness Evaluating: 15 of 31
Fitness Evaluating: 16 of 31
Fitness Evaluating: 17 of 31
Fitness Evaluating: 18 of 31
Fitness Evaluating: 19 of 31
Fitness Evaluating: 20 of 31
Fitness Evaluating: 21 of 31
Fitness Evaluating: 22 of 31
Fitness Evaluating: 23 of 31
Fitness Evaluating: 24 of 31
Fitness Evaluating: 25 of 31
Fitness Evaluating: 26 of 31
Fitness Evaluating: 27 of 31
Fitness Evaluating: 28 of 31
Fitness Evaluating: 29 of 31
Fitness Evaluating: 30 of 31
fitness out size: 31 0
Eliminate: 25
Mate Loop complete: 25
Mutate: 0
Fitness Evaluating: 0 of 31
Fitness Evaluating: 1 of 31
Fitness Evaluating: 2 of 31
Fitness Evaluating: 3 of 31
Fitness Evaluating: 4 of 31
Fitness Evaluating: 5 of 31
Fitness Evaluating: 6 of 31
Fitness Evaluating: 7 of 31
Fitness Evaluating: 8 of 31
Fitness Evaluating: 9 of 31
Fitness Evaluating: 10 of 31
Fitness Evaluating: 11 of 31
Fitness Evaluating: 12 of 31
Fitness Evaluating: 13 of 31
Fitness Evaluating: 14 of 31
Fitness Evaluating: 15 of 31
Fitness Evaluating: 16 of 31
Fitness Evaluating: 17 of 31
Fitness Evaluating: 18 of 31
Fitness Evaluating: 19 of 31
Fitness Evaluating: 20 of 31
Fitness Evaluating: 21 of 31
Fitness Evaluating: 22 of 31
Fitness Evaluating: 23 of 31
Fitness Evaluating: 24 of 31
Fitness Evaluating: 25 of 31
Fitness Evaluating: 26 of 31
Fitness Evaluating: 27 of 31
Fitness Evaluating: 28 of 31
Fitness Evaluating: 29 of 31
Fitness Evaluating: 30 of 31
fitness out size: 31 0
fitness: 0.99612688166
A: 9.817B: -0.681Critical Time: 365.323m: 0.207c: -0.023omega: 12.241phi: 4.25
fitness: 0.99612688166
A: 9.817B: -0.681Critical Time: 365.323m: 0.207c: -0.023omega: 12.241phi: 4.25
fitness: 0.99653502204
A: 9.8B: -0.667Critical Time: 365.405m: 0.209c: -0.023omega: 12.267phi: 4.105
data = pd.DataFrame({'Date':values[0].getDataSeries()[0],'Index':values[0].getDataSeries()[1],'Fit1':values[0].getExpData(),'Fit2':values[1].getExpData(),'Fit3':values[2].getExpData()})
data = data.set_index('Date')
data.plot(figsize=(14,8))
<matplotlib.axes.AxesSubplot at 0x663c250>
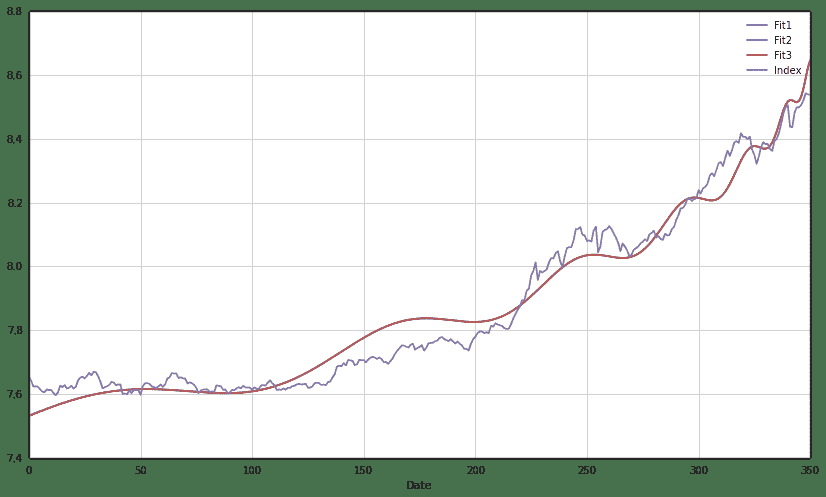
模型预测的临界时间(Critical Time)为365,即为6月10日(350)之后的15个交易日左右。实际股灾时间为6月15日(353),比实际结果晚10个交易日左右。
lib库代码,请保存并命名为lppltool
#code created by jd8001
#reference: https://github.com/jd8001/LPPL
#kindly thank jd8001!
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import fmin_tnc
import random
import pandas as pd
from pandas import Series, DataFrame
import datetime
import itertools
SP = DataAPI.MktIdxdGet(ticker='000001',beginDate='20140101',endDate='20150610',field=["tradeDate","closeIndex"],pandas="1")
global date = SP.tradeDate
time = np.linspace(0, len(SP)-1, len(SP))
close = [np.log(SP.closeIndex[i]) for i in range(len(SP))]
global DataSeries
DataSeries = [time, close]
def lppl (t,x): #return fitting result using LPPL parameters
a = x[0]
b = x[1]
tc = x[2]
m = x[3]
c = x[4]
w = x[5]
phi = x[6]
return a + (b*np.power(tc - t, m))*(1 + (c*np.cos((w *np.log(tc-t))+phi)))
def func(x):
delta = [lppl(t,x) for t in DataSeries[0]] #生成lppl时间序列
delta = np.subtract(delta, DataSeries[1]) #将生成的lppl时间序列减去对数指数序列
delta = np.power(delta, 2)
return np.sum(delta) #返回拟合均方差
class Individual:
'base class for individuals'
def __init__ (self, InitValues):
self.fit = 0
self.cof = InitValues
def fitness(self): #
try:
cofs, nfeval, rc = fmin_tnc(func, self.cof, fprime=None,approx_grad=True, messages=0) #基于牛顿梯度下山的寻找函数最小值
self.fit = func(cofs)
self.cof = cofs
except:
#does not converge
return False
def mate(self, partner): #交配
reply = []
for i in range(0, len(self.cof)): # 遍历所以的输入参数
if (random.randint(0,1) == 1): # 交配,0.5的概率自身的参数保留,0.5的概率留下partner的参数,即基因交换
reply.append(self.cof[i])
else:
reply.append(partner.cof[i])
return Individual(reply)
def mutate(self): #突变
for i in range(0, len(self.cof)-1):
if (random.randint(0,len(self.cof)) <= 2):
#print "Mutate" + str(i)
self.cof[i] += random.choice([-1,1]) * .05 * i #突变
def PrintIndividual(self): #打印结果
#t, a, b, tc, m, c, w, phi
cofs = "A: " + str(round(self.cof[0], 3))
cofs += "B: " + str(round(self.cof[1],3))
cofs += "Critical Time: " + str(round(self.cof[2], 3))
cofs += "m: " + str(round(self.cof[3], 3))
cofs += "c: " + str(round(self.cof[4], 3))
cofs += "omega: " + str(round(self.cof[5], 3))
cofs += "phi: " + str(round(self.cof[6], 3))
return "fitness: " + str(self.fit) +"\n" + cofs
#return str(self.cof) + " fitness: " + str(self.fit)
def getDataSeries(self):
return DataSeries
def getExpData(self):
return [lppl(t,self.cof) for t in DataSeries[0]]
def getTradeDate(self):
return date
def fitFunc(t, a, b, tc, m, c, w, phi):
return a - (b*np.power(tc - t, m))*(1 + (c*np.cos((w *np.log(tc-t))+phi)))
class Population:
'base class for a population'
LOOP_MAX = 1000
def __init__ (self, limits, size, eliminate, mate, probmutate, vsize):
'seeds the population'
'limits is a tuple holding the lower and upper limits of the cofs'
'size is the size of the seed population'
self.populous = []
self.eliminate = eliminate
self.size = size
self.mate = mate
self.probmutate = probmutate
self.fitness = []
for i in range(size):
SeedCofs = [random.uniform(a[0], a[1]) for a in limits]
self.populous.append(Individual(SeedCofs))
def PopulationPrint(self):
for x in self.populous:
print x.cof
def SetFitness(self):
self.fitness = [x.fit for x in self.populous]
def FitnessStats(self):
#returns an array with high, low, mean
return [np.amax(self.fitness), np.amin(self.fitness), np.mean(self.fitness)]
def Fitness(self):
counter = 0
false = 0
for individual in list(self.populous):
print('Fitness Evaluating: ' + str(counter) + " of " + str(len(self.populous)) + " \r"),
state = individual.fitness()
counter += 1
if ((state == False)):
false += 1
self.populous.remove(individual)
self.SetFitness()
print "\n fitness out size: " + str(len(self.populous)) + " " + str(false)
def Eliminate(self):
a = len(self.populous)
self.populous.sort(key=lambda ind: ind.fit)
while (len(self.populous) > self.size * self.eliminate):
self.populous.pop()
print "Eliminate: " + str(a- len(self.populous))
def Mate(self):
counter = 0
while (len(self.populous) <= self.mate * self.size):
counter += 1
i = self.populous[random.randint(0, len(self.populous)-1)]
j = self.populous[random.randint(0, len(self.populous)-1)]
diff = abs(i.fit-j.fit)
if (diff < random.uniform(np.amin(self.fitness), np.amax(self.fitness) - np.amin(self.fitness))):
self.populous.append(i.mate(j))
if (counter > Population.LOOP_MAX):
print "loop broken: mate"
while (len(self.populous) <= self.mate * self.size):
i = self.populous[random.randint(0, len(self.populous)-1)]
j = self.populous[random.randint(0, len(self.populous)-1)]
self.populous.append(i.mate(j))
print "Mate Loop complete: " + str(counter)
def Mutate(self):
counter = 0
for ind in self.populous:
if (random.uniform(0, 1) < self.probmutate):
ind.mutate()
ind.fitness()
counter +=1
print "Mutate: " + str(counter)
self.SetFitness()
def BestSolutions(self, num):
reply = []
self.populous.sort(key=lambda ind: ind.fit)
for i in range(num):
reply.append(self.populous[i])
return reply;
random.seed()
